
Are We Running Out of Data for LLMs?
For years, the recipe for building better LLMs was simple: collect more data, train a larger model, and expect better performance. That approach may soon reach its natural limit. Research such as Will We Run Out of Data? suggests that the pool of high-quality, human-generated text could be largely consumed within this decade. The internet is no longer an endless source of linguistic diversity; much of it has already been scraped, filtered, and reused.
At the same time, a growing share of new online content is now written by models themselves. This raises a new challenge: how do we keep improving LLMs when fresh, reliable human text is becoming scarce, and synthetic text increasingly fills the web? Are we heading toward a ceiling in progress, or do we still have tools to push the frontier further?
What follows examines the evolving strategies that keep LLMs improving even as natural data sources begin to dry up.

This post is part of the Generative AI Lab, a public repository that explores creative and practical uses of LLMs, Vision-Language Models (VLMs), and multimodal AI pipelines. If you are curious about how these systems can be chained together to automate creative workflows, feel free to explore the other blogs in the repository to discover more exciting applications.
📚 Table of Contents
- 🌐 The Data Frontier Has Shifted
- ⚖️ Beyond Scale: The Quality Imperative
- 🧪 Synthetic Data: Building New Fuel for LLMs
- 🚀 The Road Ahead for LLM Data
🌐 The Data Frontier Has Shifted
The era of effortless data accumulation has ended. The internet, once an open field of linguistic abundance, has been largely mined. The challenge ahead is no longer to discover more text, but to decide what kind of text deserves to shape the intelligence we are building. The question has shifted from how much data exists to how well it is curated, documented, and shared.
Recent work such as Towards Best Practices for Open Datasets for LLM Training argues that training data should be viewed as a form of public infrastructure. Just as scientific progress relies on transparent methods and replicable experiments, the progress of LLMs now depends on open, well-governed datasets that reflect shared values of quality, ethics, and inclusivity.
In computer vision, ImageNet offered a single, shared foundation for progress. LLMs have no direct equivalent, but their future depends on how coherently we structure and organize the vast data that already exists.
Yang Liu et al. conducted a comprehensive review of 303 datasets across 32 domains and observed that the rapid development of LLMs has outpaced the creation of a cohesive ecosystem for pre-training corpora. The study calls for a robust and standardized dataset ecosystem to ensure reproducibility and comparability across projects.
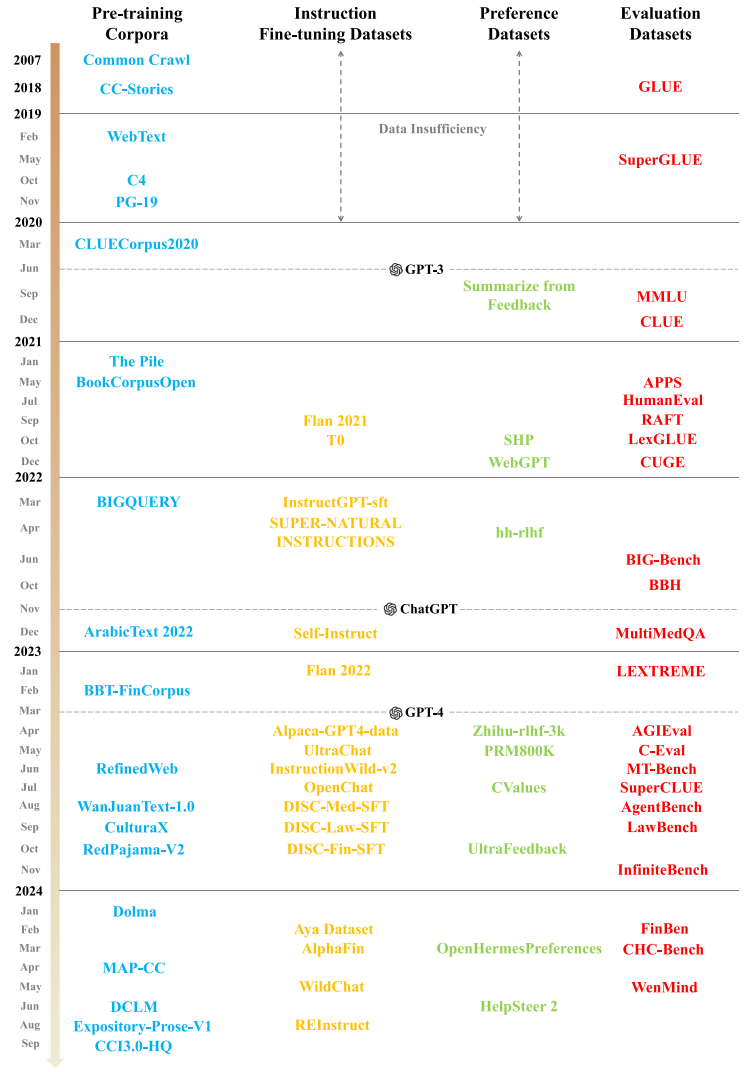
Timeline of representative LLM datasets. Adapted from Yang Liu et al. (2025).
⚖️ Beyond Scale: The Quality Imperative
The focus of progress in LLM development is shifting from scaling up to refining what we already have. Adding more tokens or larger models no longer guarantees better performance. With most large-scale corpora already assembled and reused, the limiting factor is not data volume but data integrity: how accurate, diverse, and representative the training material is. In this new phase, improvement depends on filtering, balancing, and validating data rather than expanding it.
📉 From Volume to Cleanliness
Recent work reveals that the largest efficiency gains come not from adding data but from removing it. Meta’s D4 project demonstrated that document-level deduplication and selective repetition can improve accuracy and training efficiency by more than 20%. Similarly, SoftDedup shows that reweighting redundant text, rather than discarding it entirely, achieves baseline performance with roughly a quarter fewer training steps. The conclusion is consistent: redundancy inflates compute cost without adding linguistic value.
Open pipelines now institutionalize this principle. RefinedWeb filtered and deduplicated raw CommonCrawl data so effectively that its resulting corpus rivaled curated academic datasets while still spanning over five trillion usable tokens. GneissWeb extends this approach at even larger scale, combining sharded substring deduplication with a stack of content filters to systematically raise downstream benchmark scores. Cleanliness, not sheer volume, has become the new optimization target.
🎨 Diversity as a Dimension of Quality
Quality is not just about what is removed; it is about what remains. The Diversity Coefficient introduced in Beyond Scale formalizes diversity as a measurable property of data, showing that linguistic variability correlates directly with model generalization. More recent analyses, such as We Need to Measure Data Diversity in NLP—Better and Broader, argue that diversity should be tracked across genre, domain, and cultural axes, not merely vocabulary statistics. In practice, this means that balanced representation, across topics, styles, and viewpoints, becomes an explicit quality metric, not an incidental byproduct.
⏳ Relevance and Temporal Freshness
Data quality also decays over time. A Pretrainer’s Guide to Training Data finds that temporal drift between training data and evaluation benchmarks reduces performance even in LLMs. Combining heterogeneous, time-staggered sources, e.g. books, academic text, technical discussions, recent web data, restores robustness and factual recall. Quality, in this sense, is dynamic: relevance is a moving target, not a static attribute.
🌍 Multilingual Robustness
Clean and diverse data in English do not guarantee quality elsewhere. Quality at a Glance revealed that many low-resource web corpora contain less than half usable sentences, with some offering none at all. More recent work, such as Judging Quality Across Languages (JQL), shows that model-guided filtering outperforms rule-based heuristics for multilingual data, generalizing effectively to unseen languages. Controlling for quality across languages also narrows the performance gap between bilingual and monolingual models, as shown in Assessing the Role of Data Quality in Training Bilingual Language Models. The implication is clear: linguistic equity requires targeted filtering, not uniform thresholds.
🛡️ Safety, Compliance, and Evaluation Hygiene
High-quality data also means data a model should learn from. The Dolma dataset and the NeMo Curator framework both treat safety filters, such as language identification, PII removal, toxicity, and content screening, as integral to their pipelines, not as afterthoughts. Their findings show that each layer of filtering measurably alters model behavior and social bias patterns. Meanwhile, projects like Ultra-FineWeb emphasize verification: fast feedback loops that test whether new filters genuinely improve model learning, closing the gap between curation and evaluation. Quality, in this operational sense, becomes a system of checks and iteration rather than a fixed label.
🧪 Synthetic Data: Building New Fuel for LLMs
When the internet runs dry, models start making their own water. Synthetic data, i.e. text generated by models to train newer models, has become the natural successor to web-scale scraping. Early studies such as Generating Datasets with Pretrained Language Models and Unnatural Instructions showed that well-prompted models can produce high-quality task data with little or no human annotation. More recent work, from TarGEN to MetaSynth, treats generation as controlled design rather than imitation: prompts, scaffolds, and multi-agent systems create data with deliberate structure, diversity, and domain focus. In short, the next supply of training material will be manufactured, not mined.
Controlling this manufactured data has become its own discipline. Scaling Laws of Synthetic Data and Demystifying Synthetic Data in LLM Pre-training both show that purely synthetic corpora quickly hit diminishing returns, while mixed datasets (i.e. roughly one-third synthetic) achieve the best downstream results. Diversity remains the stabilizer: On the Diversity of Synthetic Data and MetaSynth find that variety in style, topic, and reasoning improves generalization as much as raw quantity. The emerging consensus is clear: synthetic data works only when guided by explicit quality controls: balanced mixtures with real text, diversity scoring, human-in-the-loop review, and verification loops such as those explored in Evaluating Language Models as Synthetic Data Generators.
Yet, the promise carries real risk. The Nature paper: AI Models Collapse When Trained on Recursively Generated Data warns that models trained repeatedly on their own outputs undergo “distributional collapse”: loss of diversity, factual drift, and irreversible degradation. Unchecked reuse of synthetic corpora amplifies biases and erodes truthfulness according to The Definitive Guide to Synthetic Data Generation.
Synthetic data is not a shortcut to intelligence but a new medium for cultivating it. If curated with transparency, diversity, and restraint, it can extend the lifespan of progress beyond the limits of human text. If pursued recklessly, it risks turning LLMs into echoes of their own echoes.
🚀 The Road Ahead for LLM Data
The rapid phase of data accumulation is ending. Future progress will depend on how effectively we manage, curate, and extend what remains. Open access to structured datasets can make pretraining more transparent and reproducible. Careful filtering, auditing, and balancing can maintain quality where quantity can no longer grow. Synthetic data, used responsibly, can fill gaps and test boundaries without corrupting the foundations of learning.
In practice, the challenge ahead is not to find more data but to handle existing data more intelligently. The work of scaling models now shifts from collecting text to engineering pipelines that preserve diversity, accuracy, and provenance. Whether or not the supply of human text runs out, the tools to keep improving are already in our hands.
Thanks for reading — I hope you found it useful and insightful.
Feel free to share feedback, connect, or explore more projects in the Generative AI Lab.